写此文时正好ads要做和Huffman编码相关的题目,故抽了点时间实现了一个Huffman编码,并通过此文讲讲Huffman编码的算法原理。
What is Huffman Tree? 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小 ,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
Application 由于霍夫曼树树带权路径长度最短的树,我们就可以用这个方法进行编码:我们把出现次数当作权,出现次数越多的字母离根越近,也就是说码元越少。
同时,霍夫曼编码是一种前缀编码 (即要求一个字符的编码不能是另一个字符编码的前缀),这样能保证编码的使用。不会令一串0、1字符,解码出好多种可能。
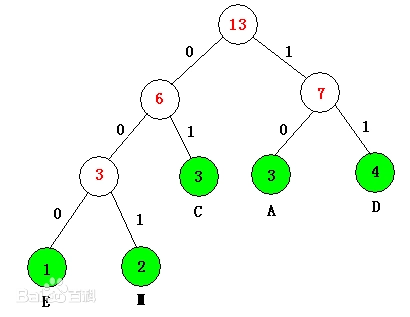
举个例子 对一串字符AAAMMCCCDDDDE,我们对其进行霍夫曼编码可得(即上图)
1 2 3 4 5 A: 10 D: 11 C: 01 E: 000 M: 001
那么编码后的数据为10101000100101010111111111000,一共是29位。
如果用传统的编码方式
1 2 3 4 5 A: 000 D: 001 C: 010 E: 011 M: 100
编码得到的数据为000000000100100010010010001001001001011,一共是39位。
**霍夫曼编码的长度是普通的74.35%!!! **
Code Implementation 鉴于需要编码的字符比较少,我选择顺势储存结构 来实现霍夫曼树。
结构体: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct HN { int weight; int parent; int left; int right; }; typedef struct HN HNode ;struct HC { int bit[MAX_BITS]; int start; }; typedef struct HC HCode ;
整体架构(main函数): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int main (int argc, const char * argv[]) cout << "Please input your text:" << endl; string text; getline (cin, text); int weight[MAX]; memset (weight, 0 , sizeof char ch[MAX]; int num_character = Num_counter (text, ch, weight); HNode huffman_node[MAX]; Create_Tree (huffman_node, weight, num_character); HCode huffman_code[MAX]; Create_Huffman_Code (huffman_code, huffman_node, num_character); Print_Code_result (huffman_code, num_character, ch); Print_After_Coding (huffman_code, ch, text, num_character); return 0 ; }
权重统计函数: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int Num_counter (string text, char ch[], int weight[]) int t_index=0 , c_index=0 , w_index=0 ; for (t_index=0 ; t_index<text.length (); t_index++) { char * pos = strchr (ch, text[t_index]); if (ch[0 ] == NULL || pos == NULL ) { ch[c_index] = text[t_index]; weight[c_index] += 1 ; c_index++; } else { w_index = pos - ch ; weight[w_index] += 1 ; } } ch[c_index] = '\0' ; return c_index; }
建立霍夫曼树: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 void Create_Tree (HNode huffman_node[], int weight[], int num_character) int m = num_character * 2 - 1 ; int node_index; for (node_index=0 ; node_index<m; node_index++) { if (node_index < num_character) { huffman_node[node_index].weight = weight[node_index]; huffman_node[node_index].parent = -1 ; huffman_node[node_index].left = -1 ; huffman_node[node_index].right = -1 ; } else { huffman_node[node_index].weight = 0 ; huffman_node[node_index].parent = -1 ; huffman_node[node_index].left = -1 ; huffman_node[node_index].right = -1 ; } } int s1, s2; for (int i=num_character; i<m; i++) { select (huffman_node, i-1 , &s1, &s2); huffman_node[s1].parent = i; huffman_node[s2].parent = i; huffman_node[i].left = s1; huffman_node[i].right = s2; huffman_node[i].weight = huffman_node[s1].weight + huffman_node[s2].weight; } } void select (HNode huffman_node[], int range, int *s1, int *s2) int min1, min2; min1 = min2 = 1000 ; for (int i=0 ; i<=range; i++) { if (huffman_node[i].weight < min1 && huffman_node[i].parent == -1 ) { min1 = huffman_node[i].weight; *s1 = i; } } for (int i=0 ; i<=range; i++) { if (huffman_node[i].weight < min2 && huffman_node[i].parent == -1 && i!=*s1) { min2 = huffman_node[i].weight; *s2 = i; } } }
编码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void Create_Huffman_Code (HCode huffman_code[], HNode huffman_node[], int num_character) int start, c, f; for (int i=0 ; i<num_character; i++) { start = num_character - 2 ; for (c=i, f=huffman_node[i].parent; f!=-1 ; c=f, f=huffman_node[f].parent) { if (c == huffman_node[f].left) huffman_code[i].bit[start--] = 0 ; else huffman_code[i].bit[start--] = 1 ; } huffman_code[i].start = start + 1 ; } }
输出编码结果: 1 2 3 4 5 6 7 8 9 10 void Print_Code_result (HCode huffman_code[], int num_character, char ch[]) for (int i=0 ; i<num_character; i++) { printf ("%c的Huffman编码是:" , ch[i]); for (int j=huffman_code[i].start; j<num_character-1 ; j++) printf ("%d" , huffman_code[i].bit[j]); printf ("\n" ); } }
输出字符串编码的结果: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void Print_After_Coding (HCode huffman_code[], char ch[], string text, int num_character) printf ("字符串Huffman编码结果是:\n" ); int c_index=0 ; for (int i=0 ; i<text.length (); i++) { int k; for (k=0 ; k<num_character; k++) { if (ch[k] == text[i]) break ; } for (int j=huffman_code[k].start; j<num_character-1 ; j++) { printf ("%d" , huffman_code[k].bit[j]); } } printf ("\n" ); }
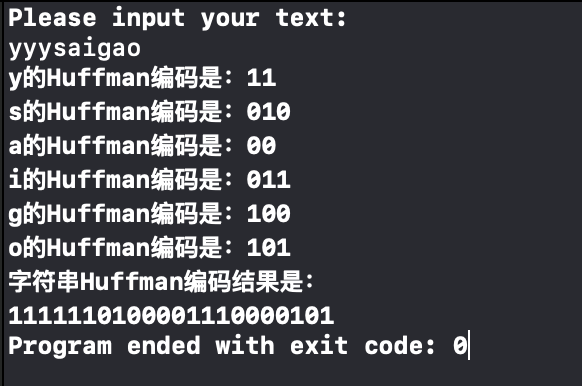
运行结果
这个程序只是一个样例,不能文件读取,不能译码(毕竟Huffman编码方式不唯一,要译码得按我这种编码的才能翻译,就懒得写了),同时对只有一种字符的时候无法编码(这应该很好解决,但是我也懒得整了)。
附录(完整代码) huffCode.h 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #ifndef __HUFFMAN__ #define __HUFFMAN__ #include <iostream> #include <cstdio> using namespace std;#define MAX 64 #define MAX_BITS MAX-1 struct HN { int weight; int parent; int left; int right; }; typedef struct HN HNode ;struct HC { int bit[MAX_BITS]; int start; }; typedef struct HC HCode ;int Num_counter (string text, char ch[], int weight[]) void Create_Tree (HNode huffman_node[], int weight[], int num_character) void Create_Huffman_Code (HCode huffman_code[], HNode huffman_node[], int num_character) void select (HNode huffman_node[], int range, int *s1, int *s2) void Print_Code_result (HCode huffman_code[], int num_character, char ch[]) void Print_After_Coding (HCode huffman_code[], char ch[], string text, int num_character) #endif
huffCode.cpp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 #include "huffCode.h" int Num_counter (string text, char ch[], int weight[]) int t_index=0 , c_index=0 , w_index=0 ; for (t_index=0 ; t_index<text.length (); t_index++) { char * pos = strchr (ch, text[t_index]); if (ch[0 ] == NULL || pos == NULL ) { ch[c_index] = text[t_index]; weight[c_index] += 1 ; c_index++; } else { w_index = pos - ch ; weight[w_index] += 1 ; } } ch[c_index] = '\0' ; return c_index; } void Create_Tree (HNode huffman_node[], int weight[], int num_character) int m = num_character * 2 - 1 ; int node_index; for (node_index=0 ; node_index<m; node_index++) { if (node_index < num_character) { huffman_node[node_index].weight = weight[node_index]; huffman_node[node_index].parent = -1 ; huffman_node[node_index].left = -1 ; huffman_node[node_index].right = -1 ; } else { huffman_node[node_index].weight = 0 ; huffman_node[node_index].parent = -1 ; huffman_node[node_index].left = -1 ; huffman_node[node_index].right = -1 ; } } int s1, s2; for (int i=num_character; i<m; i++) { select (huffman_node, i-1 , &s1, &s2); huffman_node[s1].parent = i; huffman_node[s2].parent = i; huffman_node[i].left = s1; huffman_node[i].right = s2; huffman_node[i].weight = huffman_node[s1].weight + huffman_node[s2].weight; } } void select (HNode huffman_node[], int range, int *s1, int *s2) int min1, min2; min1 = min2 = 1000 ; for (int i=0 ; i<=range; i++) { if (huffman_node[i].weight < min1 && huffman_node[i].parent == -1 ) { min1 = huffman_node[i].weight; *s1 = i; } } for (int i=0 ; i<=range; i++) { if (huffman_node[i].weight < min2 && huffman_node[i].parent == -1 && i!=*s1) { min2 = huffman_node[i].weight; *s2 = i; } } } void Create_Huffman_Code (HCode huffman_code[], HNode huffman_node[], int num_character) int start, c, f; for (int i=0 ; i<num_character; i++) { start = num_character - 2 ; for (c=i, f=huffman_node[i].parent; f!=-1 ; c=f, f=huffman_node[f].parent) { if (c == huffman_node[f].left) huffman_code[i].bit[start--] = 0 ; else huffman_code[i].bit[start--] = 1 ; } huffman_code[i].start = start + 1 ; } } void Print_Code_result (HCode huffman_code[], int num_character, char ch[]) for (int i=0 ; i<num_character; i++) { printf ("%c的Huffman编码是:" , ch[i]); for (int j=huffman_code[i].start; j<num_character-1 ; j++) printf ("%d" , huffman_code[i].bit[j]); printf ("\n" ); } } void Print_After_Coding (HCode huffman_code[], char ch[], string text, int num_character) printf ("字符串Huffman编码结果是:\n" ); int c_index=0 ; for (int i=0 ; i<text.length (); i++) { int k; for (k=0 ; k<num_character; k++) { if (ch[k] == text[i]) break ; } for (int j=huffman_code[k].start; j<num_character-1 ; j++) { printf ("%d" , huffman_code[k].bit[j]); } } printf ("\n" ); }
main.cpp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include "huffCode.h" int main (int argc, const char * argv[]) cout << "Please input your text:" << endl; string text; getline (cin, text); int weight[MAX]; memset (weight, 0 , sizeof char ch[MAX]; int num_character = Num_counter (text, ch, weight); HNode huffman_node[MAX]; Create_Tree (huffman_node, weight, num_character); HCode huffman_code[MAX]; Create_Huffman_Code (huffman_code, huffman_node, num_character); Print_Code_result (huffman_code, num_character, ch); Print_After_Coding (huffman_code, ch, text, num_character); return 0 ; }